
二つ以上のデータフレームを結合し、データをクリーニングする際、よく必要となるデータフレーム内の異なる列間で値の一致、不一致を調べる関数を紹介します。
一致のみならず、大小比較も等式を変更するだ、応用の範囲の広い関数例です。
問題の所在
以下のようなケースを想定しています。
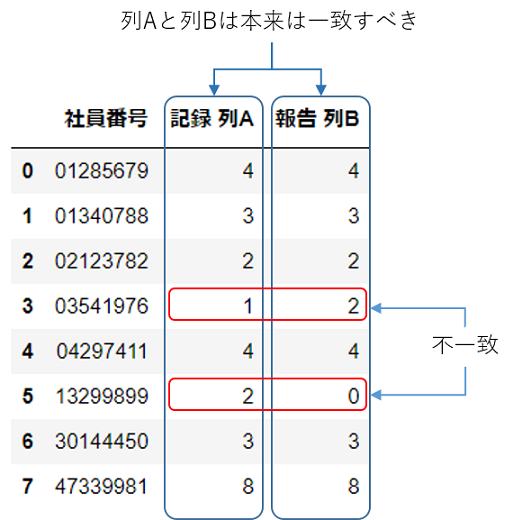
関数を定義する
if row['記録 列A'] == row['報告 列B']: の等式== で一致であれば、1を返し、不一致の場合は9を返すようにしています。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def func_row_check(row):
"""
列間を比較する
引数:
row['col1']: 比較したい列名 col1
row['col2']: 比較したいもう一つの列名 col2
Returns:
1 : 一致
9 : 不一致
"""
if row['記録 列A'] == row['報告 列B']:
return 1
else:
return 9
上図はコメントを入れた関数になっています。実際に必要なコードはLine #1,13,14,15,16 だけで十分です。簡単ですね。
関数を適用する
関数を適用した結果は、列名「結果」という新しい列に内容を追加します。
df['結果'] = df.apply(func_row_check, axis=1)データフレームで内容を確認

サンプルコード(練習用データ付き)
サンプルコードでは、データフレームの作成から、関数の定義と適用、結果の確認までを紹介していますので、お手元の Python 環境(Jupyrt Notebook 等)でお確かめくださいませ。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 必要なモジュールをインポートします
import numpy as np
import pandas as pd
# 演習用のデータフレームを作成します。
df = pd.DataFrame({ '社員番号': ['01285679', '01340788', '02123782', '03541976', '04297411', '13299899', '30144450', '47339981'],
'記録 列A': [4,3,2,1,4,2,3,8],
'報告 列B': [4,3,2,2,4,0,3,8]},
index=[0, 1, 2, 3, 4, 5, 6,7])
# オリジナルのデータフレームを表示
display(df)
# 関数を定義
def func_row_check(row):
"""
列間を比較する
引数:
row['col1']: 比較したい列名 col1
row['col2']: 比較したいもう一つの列名 col2
Returns:
1 : 一致
9 : 不一致
"""
if row['記録 列A'] == row['報告 列B']:
return 1
else:
return 9
# 関数を適用
df['結果'] = df.apply(func_row_check, axis=1)
# 結果のデータフレームを表示
display(df)
[ここがポイント!]df['結果'] = df.apply(func_row_check, axis=1)でaxis=1の指定をしないと デフォルトでは、axis=0のためKeyErroで例外となってしまい関数が上手く働きません。
参照ページ一覧
このブログを作成するにあたり、以下のページを参考にしています。併せてご覧ください。
1) 先頭のゼロが抜け落ちた番号をzfillを使って修復する
2) 任意の列の計算結果を新しい列に格納 lambda
3) df.value_counts() の結果をパワポ用にビジュアル化する