
最新のPyPDF2のモジュールを利用してPDFからテキストデータを取り込み方についてまとめたいと思います。 まず、単一PDFファイルの内容をテキストファイルに書き出しについてまとめます。
次に、glob を使ったフォルダ配下の複数のPDFファイルのテキスト情報をひとつにまとめる方法を後半でご紹介します。 さらに、各々のテキスト化の最初にファイル名を挿入しています。テキスト化の参考になれば幸いです。
PyPDF2 をインストールする
PyPDF2を利用します。
通常のPIPコマンド pip install PyPDF2 でインストールできます。
今回は以下の環境で記事を書いています。
- PyPDF2 3.0.1
- python 3.9.13
- Windows 10
サンプルコードでテキストデータを抽出するPDFは下図のとおりです。
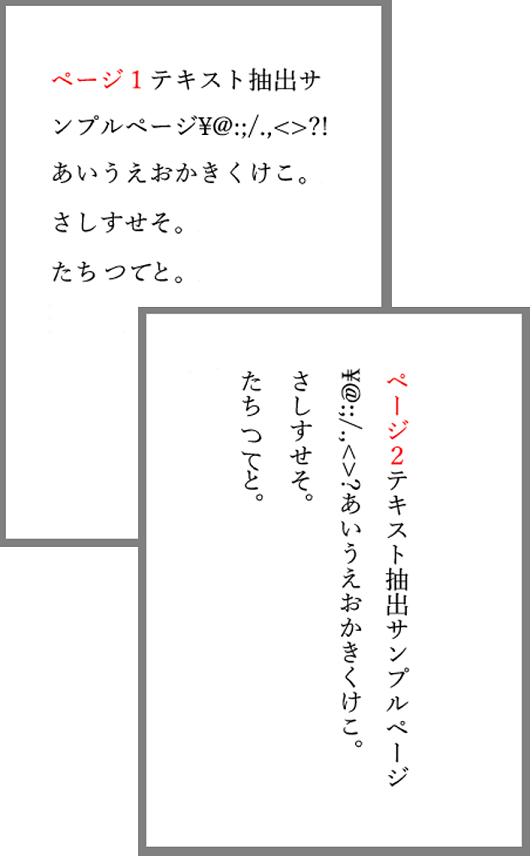
サンプルPDFには以下のような特徴があります。
- 複数のページ(今回は2ページ)から構成されている
- 縦書きと横書きが混在する。
- 日本語(全角)と記号(半角)が混在する
Input 及び Output file
サンプルコードでは、PDF(サンプル文書.pdf )をプログラムと同じディレクトリ配下に配置しています。 PDFから抽出したtxtファイル(サンプル文書.txt)も同じフォルダ配下に書き出すこととします。
サンプルコード
以下がサンプルコードになります。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from PyPDF2 import PdfReader
reader = PdfReader("サンプル文書.pdf")
all_text = []
number_of_pages = len(reader.pages)
for i in range(number_of_pages):
page = reader.pages[i]
output = page.extract_text()
all_text.append(output)
s = ''.join(all_text)
with open("サンプル文書.txt", "w", encoding ="utf_8", errors="ignore") as f:
f.write(s)
各ステップの説明
For ループで各ページ毎にテキストデータを抽出します。抽出した内容は、[‘page1’, ‘page2’, ,,,,’pageEnd’]という
リスト形式で格納します。
PyPDF2からPdfReaderをインポートします。PyPDF2を予めPIPコマンドでインストールしておく必要があります。PdfReaderを使ってターゲットの”サンプル文書.pdf”を読み込み、readerというオブジェクトに格納します。- PDFの各ページのテキストデータをページ毎に
all_textというリスト形式に格納するため、初期化します。 - ページ数を
len(reader.page)で求め、その値(今回は2)を変数number_of_pagesに格納します。 - 変数 iでページ数までのFor ループを宣言し、各ページについて以下の事を行います。
reader.page[i]:最初のページから1ページずつpageというオブジェクトに格納します。pageオブジェクトからテキストを抽出して、outputという変数に格納します。output(pdf のテキスト)をall_textにappendでリストの要素を追加します。[‘page1’, ‘page2’, ,,,,’pageEnd’]という感じでall_textが出来上がります。今回は2ページです。
s = ''.join(all_text)でリスト形式で追加されたall_textをひとつにまとめてその変数をsとします。with openで”サンプル文書.txt”というテキストファイルを定義して、オプション'w'ファイルを上書き作成します。
抽出したテキストファイル
抽出したテキストファイルをWindowsのメモ帳で開け時の内容が以下のとおりです。

[ここがポイント!<その1>]
- ワードで作成された縦書きなどの文字には各文字に 改行キーを入れて実現しているため、テキストのみを抽出した場合、文字ごとに改行がついた状態になります。
[‘page1’, ‘page2’, ,,,,’pageEnd’]というリスト形式でのテキスト化では、改行キー\nがテキストとして出現し、改行されません。- コード例のように
s = ''.join(all_text)でひとつにまとめると改行キーで改行されて見やすくなります。- いずれにしても、縦書きのテキストファイル化は避けたいところです。
Globを使ってディレクトリ配下の複数PDFを順次読み込み、テキスト化する
前半のCode ではファイル名を指定し、そのPDFファイルをテキスト化する内容でした。 しかし、複数のファイルを順次読み込み、都度テキスト化する方が 効率的です。また、ファイル名を指定しない分,手間も省けますす。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from PyPDF2 import PdfReader
import os, glob, sys
file_path = 'C:\\Users\\your_directory_to_text'
files = glob.glob(os.path.join(file_path,'*.pdf'))
for file in files:
reader = PdfReader(file)
count = len(reader.pages)
all_text = []
for i in range(count):
page = reader.pages[i]
all_text.append(page.extract_text())
newoutput = ''.join(all_text)
with open("example0221.txt", "a", encoding = "utf-8") as f:
f.write( "\n" + "\n" +"*********** " + file + " *************" + "\n" + "\n" + newoutput)
PyPDF2からPdfReaderをインポートします。os,glob,sysをインポートします。これらは、標準ライブラリですので、pip でインストール不要です。file_pathという変数名でテキスト化したいPdfが設置されているディレクトリを指定します。filesという変数に拡張子が pdf のファイルのみ順次読み込みます。for file in filesでfilesで読み込まれたそれぞれの pdf file であるfileに対してfor ループ処理をします。PdfReaderを使ってターゲットの”サンプル文書.pdf”を読み込み、readerというオブジェクトに格納します(前半と同じですね)- ページ数を
len(reader.page)で求め、その値(今回は2)を変数countに格納します (前半のコードと変数名変えています!) - PDFの各ページのテキストデータをページ毎に
all_textというリスト形式に格納するため、まず初期化します。 - 変数 iでページ数までのFor ループを宣言し、各ページについて以下の事を行います。
reader.page[i]:最初のページから1ページずつpageというオブジェクトに格納します。pageオブジェクトからテキストを抽出して、outputという変数に格納します。output(pdf のテキスト)をall_textにappendでリストの要素を追加します。[‘page1’, ‘page2’, ,,,,’pageEnd’]という感じでall_text出来上がります。今回はいずれも2ページです。
newoutput = ''.join(all_text)でリスト形式で追加されたall_textをひとつにまとめてその変数をnewoutputとします。with openで”サンプル文書.txt”というテキストファイルを定義して、オプション"a"でファイルに追加し行きます。- ファイルに書き込むにあたり、改行と**** を前後に付けてファイル名を代入しています。これでどのファイルをテキスト化したかが容易に判別できます。
テキスト抽出結果を確認する
テキスト抽出結果は、example0221.txtというファイル名で格納されますので、メモ帳で開きます。

[ここがポイント!<その2>]
- For ループを二つ入れ子(いわゆる多重ループ)で回しています。Glob でファイルの順次読み込みをしたら、そのファイルに対して各ページも順に読み込みテキスト化します
- 多重ループなのか、単純にFor ループは二つそれぞれあるかを区別させるため、Python ではインデントで識別しています
- 今回は多重ループなので、インデントが二つ奥に入り込んでいます
- 一方、ファイルの書き込みはfor file in files 単位で行うので、最初のインデントで実行しています。
- 書き込みオプション
'a'で追記するようにして、ファイル書き込みで複数のファイルの書き込みを実現しています。
参照ページ一覧
このブログを作成するにあたり、以下のページを参考にしています。併せてご覧ください。
1) PyPDF2
2) KH Coder で複合語をコントロールしてWordCloudを作成する
3) globによるファイルの順次読み込みと特定文字列のカウント