
ディレクトリ配下にある大量なApache httpサーバアクセスログをglobを使って順次読み込み、特定のファイル(語句:String)をカウントするプログラムを作成しました。ダウンロード数をアクセスログからカウントすることを想定しています。作成したプログラムの要点をBlogにまとめましたので、日次ログファイル等大量ファイルの読み込み、特定文字列のカウント等に活用してください。
Apache アクセスログ
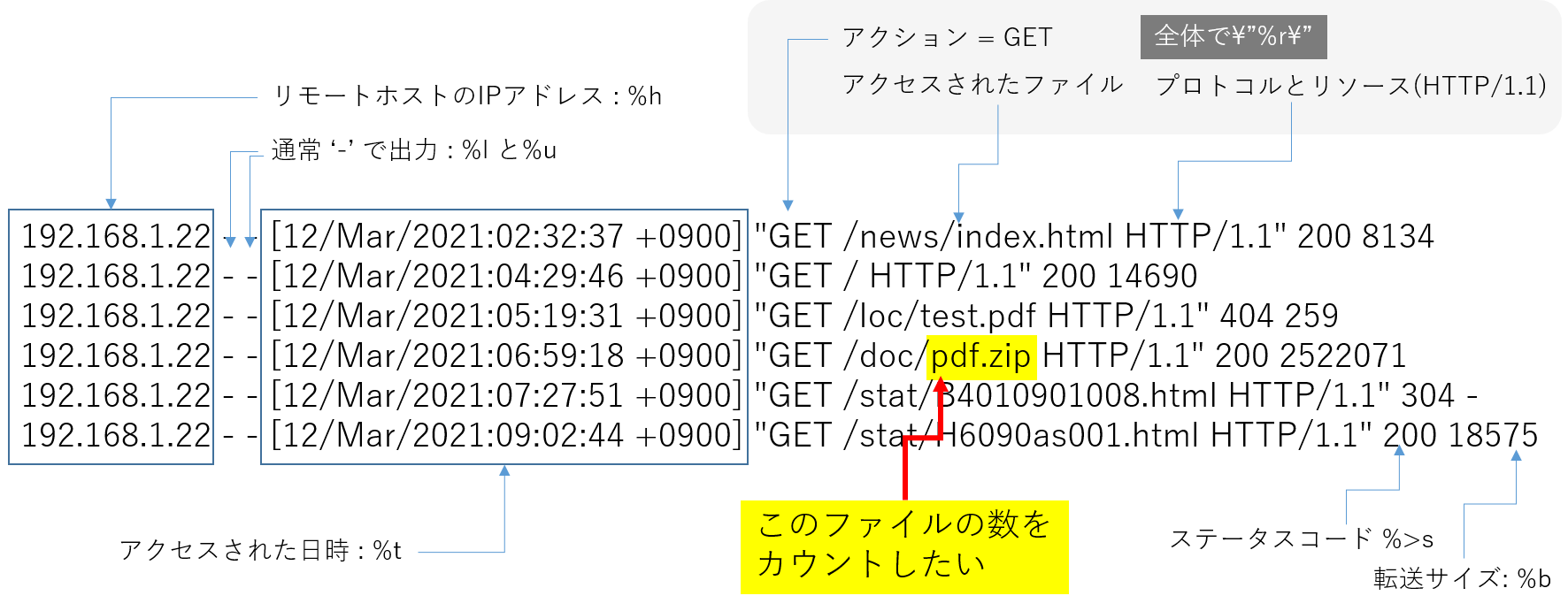
今回のプログラムで読み込むApacheアクセスログのフォーマットとカウントする箇所を以下のイメージ図のとおりまとめました。 プログラムはこのイメージ図のフォーマットで出力されるApacheアクセスログを順次、データフレームとして読み込み、特定の列(requestカラムの文字列pdf.zip)をカウントすることでファイルのダウンロード数を算出します。
集計にあたり、以下のような環境を想定してプログラムを組んでいます。
1)アクセスログは毎日、一つのcsvファイルとして出力されます
2)アクセスログのフォーマットは上図のとおりですが、解析に不要なrefererとuser agentは含めません
3)renamed_dirというディレクトリ配下に日次ファイルが溜め込まれています
4)ファイル名pdf.zipへのGETアクションのログをカウントします。
5)Read Apache HTTP server access log with Pandas の内容を参考にコーディングします。
必要なモジュールをインポートする
定番モジュールのnumpy, pandas に加えて、順次読み取りのための glob, datetime object 作成のためのdatetime, 同様にタイムゾーン(+9:00:00h)をハンドリングするためのpytzをインポートします。 今回のプログラムではディレクトリ配下のファイル(Windows)を順次読み取りします。どのディレクトリ配下のファイルを読み取るのか、ディレクトリ名を指定します。
1
2
3
4
5
6
7
8
# 必要なモジュールをインポートする
import pandas as pd
import numpy as np
import glob
from datetime import datetime
import pytz
# 読み込むファイルが属するディレクトリから指定する D:\excel_automation\
input_file_name= 'D:\\renamed_dir\*.csv'
関数を定義する
アクセスログの図解のとおり、GETアクションからプロトコルリソースまでの文字列は、ダブルクォーテーションで囲まれています。このダブルクォーテーションを取り除く関数を定義して文字列だけのColumnを作成します。
また、アクセスされた日時は、[dd/MMM/YYY:hh:mm:ss + 09000] のフォーマットです。この[]を取り除いて、Datetimeオブジェクトに変換するの関数を定義します。
アクセスログファイルは、データフレーム名dfとして読み込まれます。アクセス日時とリクエスト内容はこの定義した関数で値を変換します。関数は以下のとおりです。
1
2
3
4
5
6
7
8
9
# ダブルクォーテーションを取り除く関数
def parse_str(x):
return x[1:-1]
# []を取り除いて、Datetimeオブジェクトに変換するの関数
def parse_datetime(x):
dt = datetime.strptime(x[1:-7], '%d/%b/%Y:%H:%M:%S')
dt_tz = int(x[-6:-3])*60+int(x[-3:-1])
return dt.replace(tzinfo=pytz.FixedOffset(dt_tz))
globでファイルを順次読み込む
ディレクトリ配下のcsvファイルを順次読み込むには、glob を使います。
csv形式としてハンドリングしますが、セパレータはカンマではありません。Read Apache HTTP server access log with Pandasに詳しい説明がありますが、以下の条件でのセパレータをアクセスログのフォーマットに合わせて定義します
1)スペースで区切る。ただし、以下の条件を満たす必要がある
2)ダブルクォーテーション""で囲まれていないこと
3)大かっこ[]で囲まれていないこと
その結果セパレータの定義は以下のようになります。
sep=r'\s(?=(?:[^"]*"[^"]*")*[^"]*$)(?![^\[]*\])'プログラムは以下のようになります。実行結果として各ファイルのpdf.zipの数が読み込んだファイルの数だけプリントされます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# ダウンロードするファイル名を変数httpとして定義する
http = 'pdf.zip'
# フォルダ内のファイルを取得
for gb in glob.glob(input_file_name, recursive=True):
# print(gb) # <--デバッグ用に読み込むファイル名をプリントする
# csv ファイルとして読み込みむ
df = pd.read_csv(gb,
sep=r'\s(?=(?:[^"]*"[^"]*")*[^"]*$)(?![^\[]*\])', # separator を定義する
engine='python',
na_values='-', # "-"はNANとする
header=None,
usecols=[0, 3, 4, 5, 6], # 1,2 は "-" のため不要
names=['ip_addr', 'time', 'request', 'status', 'size'],
converters={'time': parse_datetime,
'request': parse_str,
'status': int,
'size': int
})
# カラム名"request"を変数s として定義する
s = df['request']
# カラム名"download"を設け変数sに変数httpで定義した語句があれば、true, なければfalseを返す
df['downlod']= s.str.contains(http, na=False)
# boolean値を0/1に変換する
df['downlod']= df['downlod'] *1
# 1の数を数える(1のSumを取る) 変数tot に代入する
tot = sum(df['downlod'])
# 変数tot (各ファイルのpdf.zipの数)をプリントする
print (tot)
参照ページ一覧
必要に応じて以下のページを参考にしてください。
1) Read Apache HTTP server access log with Pandas
2) PythonでExcel自動化:複数のexcelファイルの同じ場所のセルの値を一つのシートにまとめる
3) カラムデータの特定語句の有無を判定しカテゴリ化する
ひとこと
いちから作成するには、なかなかハードルの高いプログラムですが、非常に参考となる記事がネット上のありましたので、その記事を参考に、glob で順次読み取りをするところと、
s.str.contains(variable, na=False)のいずれも当サイトでまとめていたのを流用しましたので、半日程度で完成しました。この記事を参考に皆様も、日々遭遇するデータ読み込み、ハンドリングの課題をPythonで解決していただければ、幸いです。